Using specialist tech to tackle the toughest challenges in healthcare.
Introducing McCrae Tech
The new home of Orchestral and Hospitals EPR
Following Orion Health’s recent acquisition by HEALWELL AI, our Orchestral Health Intelligence Platform and Hospitals solutions now have a new home at McCrae Tech, a bold, Kiwi-owned innovation lab launched by Orion Health’s founder.
McCrae Tech blends decades of healthcare expertise with the agility of a start-up to build what generic systems can’t: modular, scale-able, data-driven tech that solves real-world challenges.
McCrae Hospitals will continue to evolve as a next-gen Hospital Information System (HIS), transforming patient administration and clinical workflows, while Orchestral remains a powerhouse health data platform built for action using AI and machine learning to engineer real clinical insights.
We’ll continue working closely with McCrae Tech to support our customers and bring world-class New Zealand-made health tech to the globe.
Curious about solutions?
Explore McCrae Tech's product offering
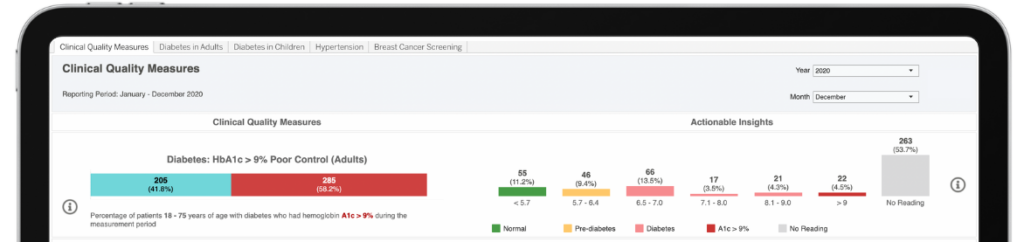
Orchestral Health Intelligence Platform
Simplifying the journey from data to trusted insights.
Our combined mission to revolutionise healthcare through AI and data-driven innovation
Orion Health and HEALWELL AI have joined forces to revolutionise healthcare through AI and data-driven innovation.
Together, we can deliver unparalleled solutions that drive efficiency, improve patient outcomes, and empower healthcare providers worldwide.
Curious about our solutions?
Explore our Unified Healthcare Platform solutions
Digital Front Door
Orion Health’s Virtuoso Digital Front Door is an omni-channel patient engagement platform that integrates tools and services for end-to-end healthcare navigation and management.
Orion Health’s Amadeus Digital Care Record provides an integrated health record that consolidates patient data across care settings, enabling enhanced care coordination and population health management.
Amadeus Direct Secure Messaging solution makes it easy to send secure health information directly to trusted recipients over the Internet, all while maintaining patient privacy and confidentiality.
Orion Health’s Clinical Workstation provides a comprehensive Hospital Information System that empowers healthcare providers to access real-time patient data securely and efficiently.
With access to HEALWELL AI’s best-in-class AI technology, Orion Health enhances data-driven healthcare, unlocking deeper insights, improving decision-making, and driving better patient outcomes at scale.